Fuel campaign performance with laser-focused targeting

Data collection is the starting point of Big Data lifecycle capture, curate, store, analyze and visualize. At InMobi data is generated by online serving systems. This could be impression, click, download or other kinds of events. This data is used for different Business applications like Billing, Reporting, Business Intelligence, Machine learning, real-time Analytics, and real-time feedback loops. This blog post is about Conduit, a system to collect the huge number of events data from online systems, making that available as real-time stream to consumers in a seamless fashion.
Earlier InMobi was using an Rsync based file push mechanism to transfer data directly to the consuming system. The granularity of files was minute. Every minute, data gets collected from online systems and get pushed to one or a set of machines. Further, these machines upload the data to HDFS. This was a very simple solution and worked well for long time, when data volumes were less and the number of consuming systems was few. As InMobi gained scale in last 2 years, the data volumes grew and the online serving systems span across multiple geographies. The data consumers also became very demanding in nature with complex and disparate needs. The consumer systems could be different Hadoop grids, HBase, the real-time consumers like fraud detection systems, streaming analytics systems etc. The point to point minutely file push model from producers to end consumers started having lot of trouble. No easy way to monitor or control the flow, if WAN links become flaky, huge backlog builds on producer machines. As the systems were very tightly coupled, any addition of new consumer would require a configuration change on the producer boxes. All destinations IP addresses need to be known on producer machines. Often the operations team managing the producer systems and consumer systems are different, so became very difficult to manage this. There were lot of operability challenges like if a box on which the Rsync is pushing the file is down, and then data flow can get choked. No easy visibility in late arriving events. This was also expensive on infrastructure. If more than one consumer in a remote data-center requires the same data stream, there would be lot of WAN bandwidth wastage for duplicate data transfers.
Last year we started looking into the above data collection issues and possible solution to address it. What we were looking for was a data collection system. We defined certain goals and characteristics of this system:
- Decouples producers and consumers. Consumer need not know about the producer systems at all and vice versa.
- Reliable and highly scalable
- Suits both batch as well as low latency streaming consumers. No different data paths. Should be Map-Reduce friendly
- Allows consumers to process the data at their own pace
- Efficient: no duplicate data transfers, uses compression
- Works with distributed producers over WAN, with consumers sitting in local or remote datacenters.
Collecting data requires a Data Relay from a producer to a storage system. There were few solutions already available in the open source. We started looking at these. The technical comparison is dated so not everything may be relevant now. The main technologies we looked at were Kafka, Flume and Scribe. After detailed evaluation, we chose Scribe. Kafka, primarily was not having replication so had to be coupled with HDFS for long term data storage. It can be done in Kafka but Scribe does this in a more first class way, as it doesn't try to store data at all. Flume NG was infancy that time.One of the reasons for choosing Scribe was also that InMobi already had some experience running Scribe in semi-production environment Conduit has a pluggable data relay layer. Currently it uses Scribe, but should be easy to write a Flume based relay. Scribe for Data Relay worked well for us. The challenge was getting the data over WAN links, which have high and variable latencies. Link itself can get flaky for long periods. So the architecture we chose is to stream the data into local Hadoop cluster in each data center. The producer application stream data to Conduit using the publisher client library. The data gets streamed into HDFS via scribe collectors. Then the data is published into minute directories in HDFS. Each event stream is referred as a topic. 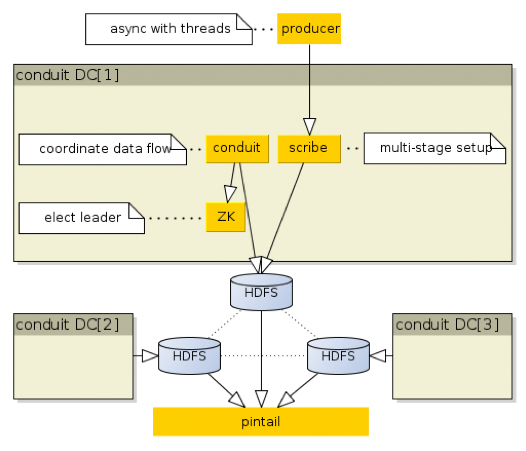
Data is published in the minute directories in HDFS for a given topic. A topic has three views for the consumers local, merged and mirror.
Local view only has data collected within the same datacenter.
Merged view has data collected from all the data-centers. Merge view is not configured by default for all topics. It is configured on demand in a cluster co-located with the consumer application.
Merge view can also be replicated in other clusters, which is called a mirror. Mirror stream can be used for BCP purpose. The data is published in HDFS in minute directories as [topicName]/yyyy/MM/dd/HH/mm This layout enables consumer systems (could be workflows) to consume data at different granularities. The latencies from the time an event is generated to the time it is available for consumption varies between 2 minutes to 5 minutes depending on the view I.e. Local, merge and mirror.
There is a streaming library called PinTail via which events can be streamed out of HDFS as they arrive. It has got much lower latencies of less than 10 seconds. It is inspired by Facebook's PTail library. Since PTail is not available in open source, we decided to write a streaming library for us. PinTail has powerful features like check pointing and consumer groups, a subject for some other time. Note: Conduit is in production for over six months at InMobi. Conduit producers span over 4 datacenters and produce over 10 billion events daily. The project is open sourcedunder Apache 2.0 License.
I want to thank Inderbir Singh and Amareshwari Sriramadasu for contributing to the project and the blog post.
Sharad heads the Technology platform group where he leads the development of Hadoop and big data platforms at InMobi. He is an Apache Hadoop PMC member. Sharad is also the organizer of Bangalore Hadoop Meetup Group.
Register to our blog updates newsletter to receive the latest content in your inbox.






![In-App Ads.txt: What You Need to Know [VIDEO]](https://web.inmobicdn.net/website/website/6.0.1/uploads/blog/app-ads.txt_video_blog_about_image.png)