Fuel campaign performance with laser-focused targeting

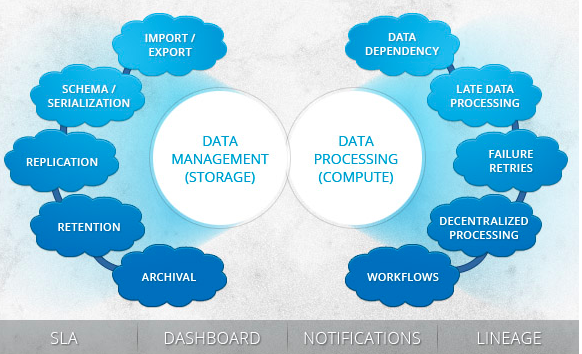
InMobi has been using big-data technologies (Apache Hadoop and its family) for the last 2.5 years for storing and analyzing large volumes of serving events / machine generated logs. InMobi receives in excess of 10 billion events (ad-serving and related) every day through multiple sources/streams originating from over ten geographically distributed data centers. In a typical day we process tens of terabytes of data. In the beginning, we had a single central data center where all the processing took place resulting in high IT costs related to servers and network bandwidth. As we explored cheaper and more effective ways of processing this huge amount of data, we came up with a simple in-house scheduler to manage job flows in our environment then. We realized that to be able to process data in a decentralized fashion, we needed to have the complexity pushed into a platform and allow the engineers to focus on the processing / business logic. Besides data processing needs, all other data management functions also became de-centralized or repeated in such a setup. So we invested time to build a data center location aware processing and data management platform, Falcon. There are numerous challenges when it comes to managing big-data. These are related to data movement (import/export, replication), retention (purge, archival), processing (late handling, workflows, geographically distributed processing) etc. Falcon has been deployed in production within InMobi for nearly a year and is being widely used for various processing pipelines and data management functions, including SLA critical feedback pipelines, correctness critical revenue pipelines besides reporting and other applications. We are excited about working with Hortonworks to incubate this project in Apache Software Foundation along with others to make it available for the larger benefit of the big-data community.
Register to our blog updates newsletter to receive the latest content in your inbox.






![In-App Ads.txt: What You Need to Know [VIDEO]](https://web.inmobicdn.net/website/website/6.0.1/uploads/blog/app-ads.txt_video_blog_about_image.png)