- Advertising
- Products & Tools
SKAN 4.0: What App Advertisers Need to Know


Another one of Apple’s Worldwide Developer Conferences (WWDC) has come and gone, and another update to SKAdNetwork (SKAN) arrives — this time with some updates that make it a far more usable solution for advertisers. If SKAN 1.0 was the Minimum Viable Product (MVP), you might now say we’re at beta release stage with SKAN 4.0 as it becomes more widely usable — a slightly different release approach to what we’re seeing with Google’s Privacy Sandbox for Android.
However, let’s dive into what was announced.
What’s new?
If you’re keeping score, here’s what we’ve seen through different SKAN releases up to now.
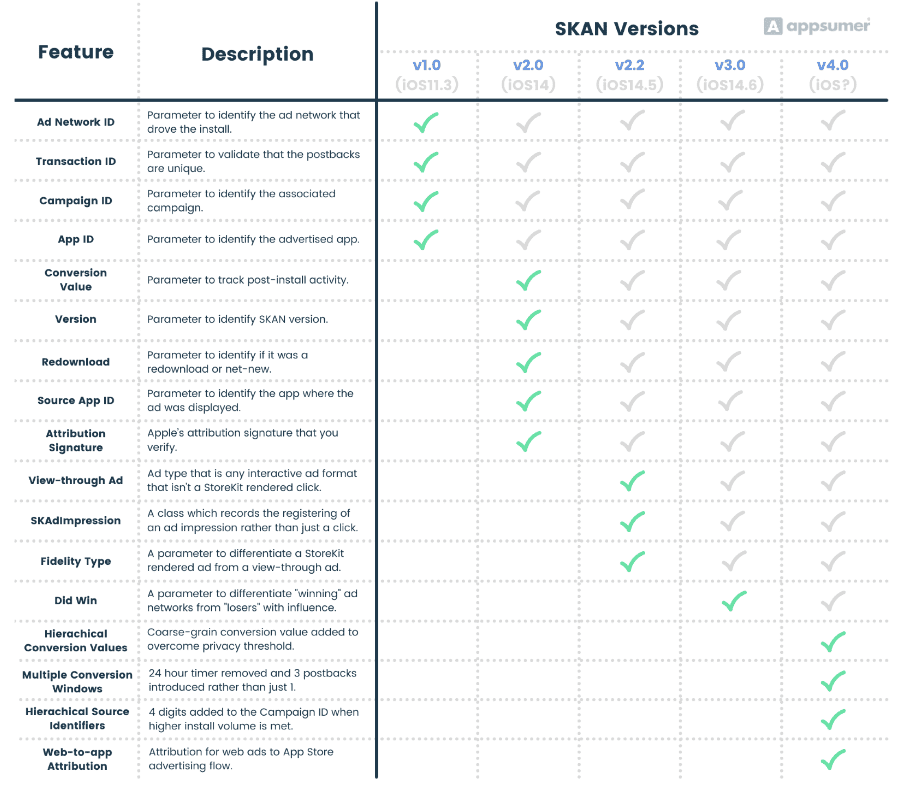
However, let’s take a more detailed look at these new features for SKAN 4.0.
Hierarchical Conversion Values
The privacy threshold has likely had the biggest negative impact on advertisers’ ability to spend on iOS post-ATT. This is because the understanding of install value was lost for a high percentage of paid installs when a certain volume of installs was not met (we suspected this privacy threshold was around 20-30 installs per campaign and 128 installs per campaign on Facebook due to their Campaign ID mechanics).
Quite a big percentage of data was lost (~20% depending on campaign granularity), so this is a very welcome feature. It is a change to Conversion Values that delivers some indication of install value even when the install volume is lower.
There are now two types of Conversion Values returned:
- Coarse-grained: When the previous privacy threshold is not met, this returns a “low”, “medium” or “high” value for the Conversion Value.
- Fine-grained: The same 64-bit value that has traditionally been used for Conversion Values will be returned when the privacy threshold is met.
In an important change, for some use cases, Conversion Values can now go up and down. Previously, they only went up.
Key considerations for advertisers:
- Small-scale testing gets easier: This does not eliminate privacy thresholds; however, it does reduce the threshold for “NULL” conversion values to be returned. Due to “crowd anonymity”, which is explained in the WWDC SKAN session, the install bar for a coarse-grained Conversion Value can be lower that a fine-grained one meaning advertisers who want to test campaigns can now get some indication of success beyond “NULL”.
- What does low, medium and high mean to you?: You can select what value you want to place on low, medium and high. An obvious approach given there are three values and six bits in a fine-grained Conversion Value might be something like the below. This way you can map coarse and fine-grained Conversion Values more easily. However, it’s time to dig into your in-app analytics to find those three key data points that map to the value of a user. The points you choose will also depend a lot on whether the conversion schema you use is revenue based (now more viable than ever), event-based or funnel-based.
Multiple Conversion Windows
A critical balance for advertisers when they only receive a single SKAN postback has been trying to capture enough information on the value of an install whilst not delaying data too long for analysis and not letting the 24 hour timer lapse through inactivity. Much like the solution Google announced, Multiple Conversion Windows means advertisers no longer have to strike this balance.
These key changes have been announced to Conversion Windows:
- The 24-hour timer has largely been removed. Thank goodness! However, your first fine-grain Conversion Value will have a 24-hour time limit. Your coarse-grain conversion values won’t have this limitation anymore though.
- Advertisers can now receive three SKAN postbacks for a single install, each with a specific Conversion Window e.g., 0-2 days 3-7 days and 8-30 days whereas previously it was a single postback.
- The 2nd and 3rd postback will only be triggered if the privacy threshold volume has been met and also will only be coarse-grained not fine-grained Conversion Values.
Key considerations for advertisers:
- Cohorts are back: A key metric for user acquisition has been looking at ROI on a cohorted basis, whether D1, D7, D30 or beyond. This was lost with previous versions of SKAN as advertisers largely were getting a postback with three days of data or less. This allows advertisers to once again start to look at ROI on a cohorted basis in tools like Appsumer. They won’t be perfect as the second and third postback will be coarse grained and with the random timer cohorting back to a specific day is impossible, however, they will give better signals than before.
Hierarchical Source Identifiers
The 2-digit Campaign ID was a limiting factor for things like testing creatives and formats, particularly on Facebook where they reserved 1 digit for their own testing. So hierarchical source identifiers adding an extra 2 digits does open up more data richness for testing creatives and formats that will be welcome.
Hierarchical source identifiers essentially expand the Campaign ID field to four digits vs two. Albeit, with caveats:
- Much like hierarchical conversion values, crowd anonymity comes into play.
- It’s believed that when a coarse-grained Conversion Value is returned you will only receive 2 digits of the Campaign ID.
- However, as install volumes increase on a campaign you will start to open up more digits for the Campaign ID.
Key consideration for advertisers:
Increase granularity with volume: To ensure you at least understand high-level campaign information even on low volume campaigns, it’s probably worth going from least granular to most granular in order of preference when structuring the Campaign ID. For example, see the below visualization.

Web-to-App Attribution
Although this hasn’t been a key demand we’ve seen from app-first advertisers, if you’re web and app hybrid then SKAN’s inability to attribute web-to-app flows has likely been a big pain point. SKAN now covers web-to-app attribution when the web ad is directed to an app’s App Store product page. A long overdue improvement for many verticals.
Wrapping up
Advertisers who have been falling back on fingerprinting can now consider that Apple has given them a final warning. A privacy session at WWDC was very clear that fingerprinting is not allowed. Whether we’ll see Apple policing the wild west of fingerprinting by rejecting app updates or by introducing technological solutions is still unclear. However, what is clear is that fingerprinting is not a grey area, it is without doubt against Apple’s policy.
Apple wants you to use SKAN and overall these are really welcome improvements for SKAN. If Apple are to clamp down on fingerprinting and SKAN becomes the dominant attribution solution for iOS, these changes make it more viable. In particular, still getting some idea of install value when the privacy threshold is not met will drive more iOS ad spend, as this has been a central challenge of SKAN.
Now is the time to get behind SKAN and what these changes introduce is far more data complexity – just within the walls of SKAN – that advertisers will need to make sense of. There will be far more normalization and unification of even more SKAN data complexity needed. This requires an additional BI data layer on top of your MMP for all advertisers to manipulate, normalize and unify this data and turn it into an apples-to-apples comparison across channels and OS’s that delivers performance insights. Just a few areas of data manipulation that this update introduces are:
- Coarse-grained and fine-grained Conversion Values introduce two new datasets that need to be unified and normalized in SKAN data. The flexible data infrastructure of a BI layer already enables the normalization and unification of SKAN and ID-based data into aggregate reports; it will also be flexible enough to normalize and unify these two datasets too.
- Performance will also need to be constantly retrospectively updated with three postbacks all with different Conversion Windows. Dealing with retrospective data updates is a solution that a flexible BI layer can handle along with cohort visualizations.
- Hierarchical source app IDs also introduce more granularity back into SKAN data that was previously lacking e.g., creative & format etc. Having a BI solution that can handle these different levels of granularity will put that data to work to generate granular insights.






![In-App Ads.txt: What You Need to Know [VIDEO]](https://web.inmobicdn.net/website/website/6.0.1/uploads/blog/app-ads.txt_video_blog_about_image.png)



Stay Up to Date
Register to our blog updates newsletter to receive the latest content in your inbox.